
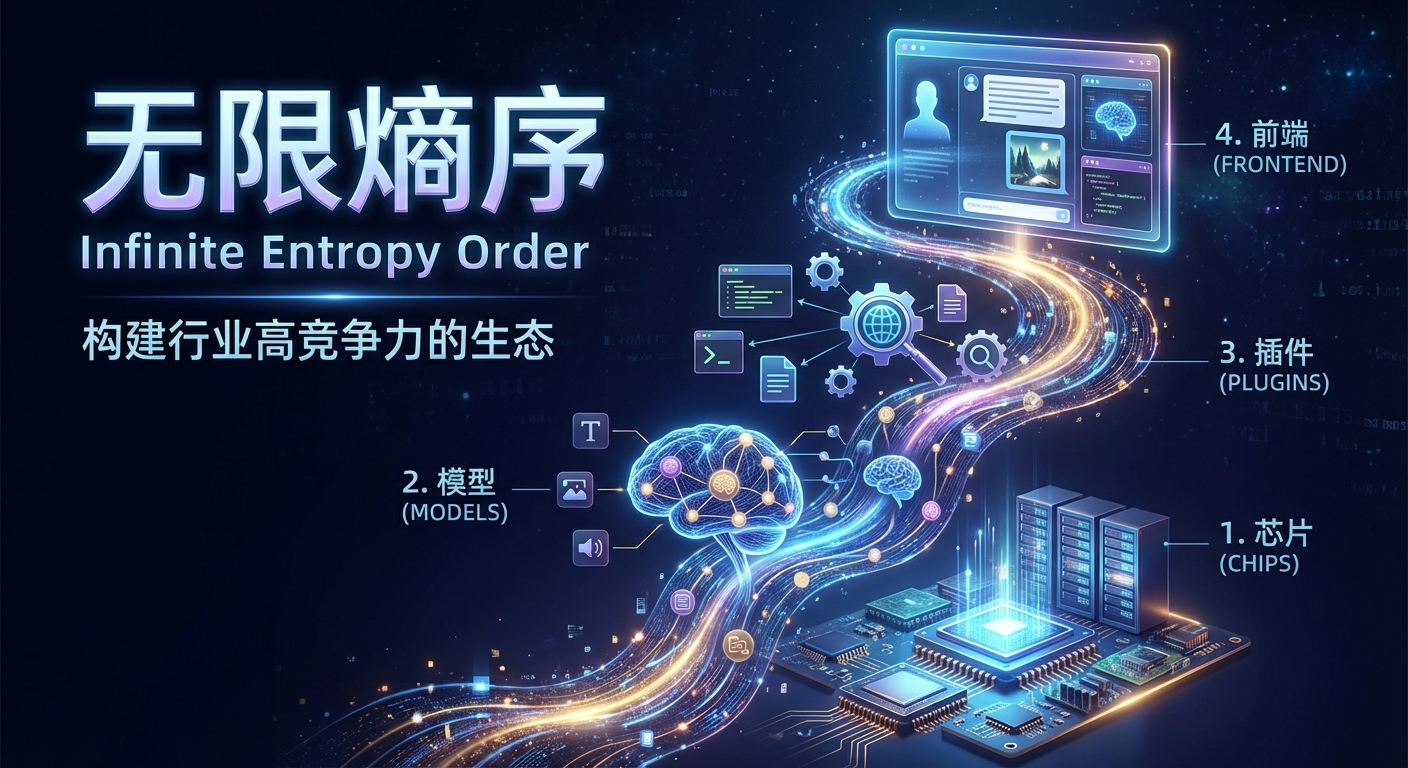
一个完整的生成式AI应用包括"芯片, 模型, 插件, 和前端", 这个行业产业链就此从上游到下游分布, 在每一个环节取得优势都可以产生巨大的商业价值.
芯片: Nvidia (训练/推理), Cerebras (推理), Groq (推理), Movement (MPU推理)
模型: OpenAI, Anthropic, xAI, DeepMind, Qwen, ChatGLM, Minimax, Kimi, Seed, Inception-AI
插件: Tavily (搜索), Bocha(搜索), MetaSo (搜索), E2B (代码沙盒), Firecrawl (爬虫), Langchain (后端开发), BrowserUse (爬虫)
前端: LobeHub, Perplexity, Cherry-Stdio, Bolt-New, Cursor, Loveable
而无限熵序致力于在每一个环节都达到行业高竞争力.
1. 插件设计
整个插件总的来说包括"搜索, 爬虫, 代码执行, 和文件读写", AI只要具备了这些能力就可以自主完成任务.
爬虫搜索
市面上有很多搜索产品, 很多模型提供商也在API中附带了搜索功能, 随之衍生而来的还有深度研究这一概念.
但影响AI搜索功能的最大因素不是人为的设计复杂的循坏迭代Agent, 而是高质量的内容都是要付费的, 但市面上的搜索API只能提供低质量的内容.
并且, 互联网上优质信息是有限的, 没有理由也没有必要通过强化微调训练一个搜索智能体, 在抓取50个结果后再去重新组织关键词进行下一轮搜索. 用户在得到了一份冗长的报告, 但缺乏强有力的参考文献支持.
为了解决以上问题, 我开发了一种通用的数据抓取方法, 可以零成本地抓取互联网上的所有信息, 包括微信公众号, 抖音, 小红书, 知乎, Bloomberg, Medium, X, Reddit等.
当网站收到一个请求时, 它会检测你的鼠标键盘操作轨迹是否像真人, 再进一步检测登录信息是否良好, 以此来判断用户的访问是通过还是阻止.
解决这一问题, 只需让AI获取用户的登录Cookies, 并以此直接请求网站的底层接口即可, 这种方法兼具了通用性和速度, 避免了AI通过操控屏幕点击来访问网站的臃肿.
这项功能通过一个异步并行函数GeneralImport来作为"Tool/Mcp/Skill"提供给AI使用, 以付费且需要登录的Medium, Zhihu, Bloomberg, X为例
await GeneralImport(["https://medium.com/mitb-for-all/its-2025-take-your-llm-apps-to-the-next-level-with-chainlit-00036c8db1ba", "https://zhuanlan.zhihu.com/p/1952376143765309335", "https://www.bloomberg.com/features/2025-japan-zombie-companies-debt/?srnd=homepage-americas", "https://x.com/madebygoogle/status/1962909623481930193"])由于每一次搜索返回的都是多个结果, 所以函数会以并行的方式同时处理多个链接以提升速度, 最后结构会以Markdown的形式返回, 并且会完整保留图片, 音频, 和视频.
结果示例 (crawler.txt).
并且支持对学术论文的抓取, 会从Sci-Hub等开放站点进行抓取, 如果没有则寻找相关性替代.
await GeneralImport(["https://www.nature.com/articles/s41467-025-63759-7"], type='scholar')由于学术论文普遍较长, 所以返回的是AI总结结果, 以避免上下文爆炸, 结果示例 (academic-crawl.txt).
导入函数GeneralImport同时支持对视频, 音频, PDF, 文件夹的导入, 结果以Markdown的形式返回.
搜索分为通用, 学术, 政经, 程度分为一般的(20个结果)和深度的(50个结果).
文件与代码读写
E2B等商业模式旨在为Agent提供一个虚拟环境, 使得Agent能够在这个环境进行自主创作.
然而, 这个技术无法构成客观的商业壁垒, 构建虚拟桌面并不是一个很难的事情.
我为模型设计了Python, Node.JS, Verilong, Terminal执行器, 再加上ContentWrite, 足以应对单文件和项目文件夹的场景.
Wolfram符号求解器替代版
GPTs从上线以来就有一个很火爆的应用Wolfram, Wolfram是世界上唯一能进行完备符号推理的函数式编程语言.
它比Lean语言更为简洁和通用, 可提供一个通用地推理范式, 而不是仅仅局限于基础数学领域.
基于Lean的强化学习模型AlphaProof和DeepSeek-Prover, 有效地提升了在数学证明题的能力.
但基础数学在实际中基本上用不到, 市场普遍需求的是计算与应用数学, 这催生了参照AlphaProof进行应用数学强化学习的想法.
由于Wolfram语言是闭源的, 且WolframAlpha的API调用价格偏高, 我基于Mathics复现了Wolfram的核心功能, 并封装为一个工具SymbolReasoner供模型推理使用.
例如, 对于一个无显示解析解的方程y'[x] - Log[y[x]] == Sin[x] Cos[x] Exp[x], Wolfram可以直接求出渐进解:
await SymbolReasoner('''AsymptoticDSolveValue[{y'[x] - Log[y[x]] == Sin[x] Cos[x] Exp[x], y[0] == 1}, y[x], {x, 0, 10}]''')
"1 + x^2/2 + x^3/2 + x^4/12 - (13*x^5)/120 - (31*x^6)/360 - (13*x^7)/504 + (39*x^8)/2240 + (55*x^9)/2016 + (30853*x^10)/3628800"2. 模型设计
DeepThought基于Qwen增量训练而成, 涉及到的方案包括持续预训练, 监督微调, 强化学习, 模态对齐, 和模型编辑, 训练框架使用了Pytorch-Lightning.
Qwen是世界上使用最为广泛的模型, 有非常多的衍生模型都基于Qwen, 比如群核科技的SpatialLM, 上海人工智能研究院的Intern, 昆仑万维的Skywork, 快手的KAT-Coder, 陈天桥所创立的MiroMind, 微博的VibeThinker, 和allenai/Olmo-3-32B-Think
包括OpenAI前CTO所创办的Thinking Machines Lab, 推出的产品, 也基于Qwen做微调服务.
DeepThought的一个核心设计理念是Model和Agent的融合, 在设计产品中体现为不需要任何的人为编排和工作流, 完全由模型自主判断, 多轮规划迭代.
因为模型就是应用本身, 从商业竞争上来讲不掌握模型开发的公司没有任何的商业价值和壁垒.
AI创业市场如坟场! 马斯克转发Reddit前CEO观点 “巨头将通吃一切”
更为核心的是, 强化学习的开创者Richard S. Sutton有一篇著名的文章The Bitter Lesson, 很好地阐述了这个观点.
这是一个重要的教训。纵观整个人工智能领域,我们仍然没有彻底地吸取它,因为我们继续犯同样的错误。为了看到这一点,并有效地抵制它,我们必须理解这些错误的吸引力。我们必须吸取苦涩的教训,即把我们认为的思维方式构建到系统中是行不通的。
苦涩的教训是基于历史观察:
1)人工智能研究人员经常试图将知识构建到他们的 Agent 中;
2)这在短期内总是有帮助的,并且对研究人员来说是个人满意的;
3)但从长远来看,它总会达到一个瓶颈,甚至会阻碍进一步的进展;
4)突破性的进展最终是通过一种相反的方法实现的,这种方法基于通过搜索和学习来扩展大规模计算。
最终的成功中夹杂着一丝苦涩和消化不全,因为它比受青睐的、以人为本的方法更成功。
从苦涩的教训中学到的一件事是通用方法的巨大力量,即随着可用算力变得非常大,这些方法会随着计算量的增加可以继续扩展。可以以这种方式近乎无限扩展的两种方法是搜索和学习。
只有通用计算方法最终是最有效的,而且优势巨大。
但长远来看,唯一重要的是利用算力。
一种更简单的、基于搜索的、结合特殊的硬件和软件的方法
通过拥抱搜索和学习,才取得更大的成功。
统计学方法战胜了基于人类知识的方法
思考和非思考模式的融合
在用户发送一个请求时, 总是要等不少的时间才能收到回复, 原因是推理模型需要经过思维链引导.
但推理模型能力的提升本质上并不是因为思维链, 而是测试时扩展, 即模型拥有更多的思考时间.
所以思考和回复本身就不应该分开, 我们只需让模型经过训练对复杂的问题产生更多的生成时间.
使用这个方法, 可以防止过度地输出Token, 并使得对话更自然, 类似的工作有 https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera#deepseek-tng-r1t2-chimera
API接口由Litestar构建, Litestar在底层提供了快速序列化以保证API服务的速度, 兼容OpenAI ChatCompletion格式.
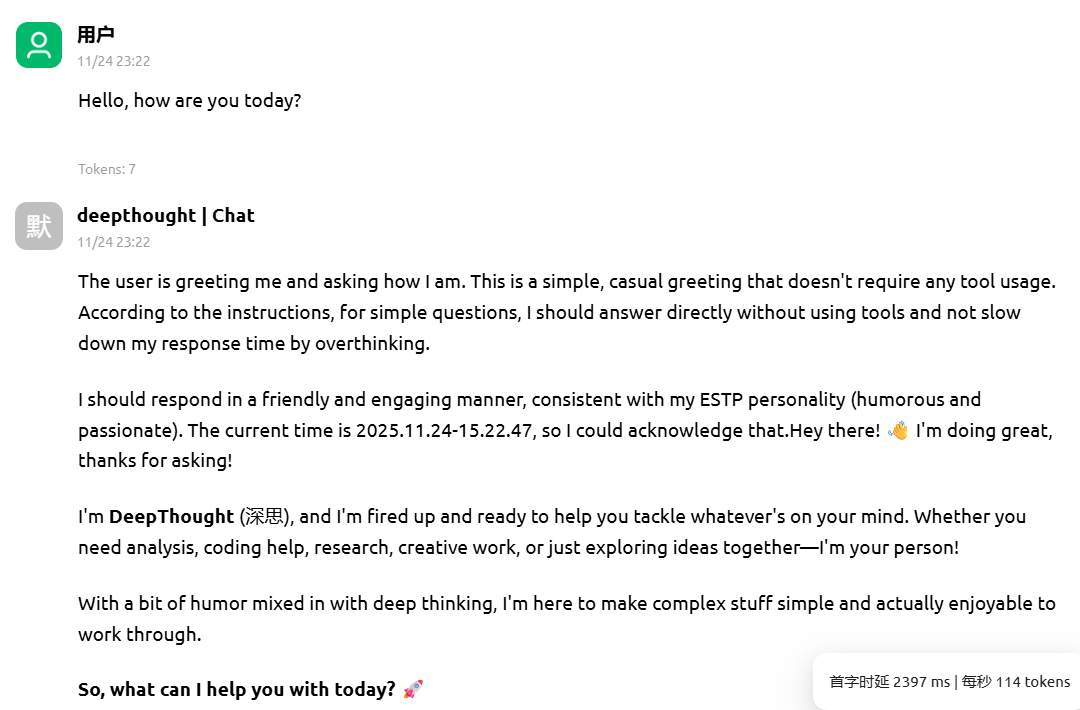
使用Cherry Stdio测试, 首字时延为2397 ms, 每秒输出114 tokens.
多模态理解和生成
通过文本, 视觉, 和语音模型的融合即可得到一个全模态模型, 类似方法例如 https://huggingface.co/ngxson/Home-Cook-Mistral-Small-Omni-24B-2507-GGUF和https://github.com/KlingTeam/VANS
from MessageConvert import FileEncode, VideoEncode, AudioEncode, ImageEncode, ConvertToPdf
# This can be your custom functions to encode media into Base64 string
file_base64 = await FileEncode("/test/test.pdf")
video_base64 = await VideoEncode("/test/test.mp4")
audio_base64 = await AudioEncode("/test/test.wav")
image_base64 = await ImageEncode("/test/test.jpg")
image_message=[{{"role": "user", "content": [{"type": "text", "text": "描述这个图片"}, {"type": "image_url", "image_url": {"url": image_base64}}]}]
audio_message = [{"role": "user", "content": [{"type": "text", "text": "描述这个音频"}, {"type": "input_audio", "input_audio": {"data": audio_base64, "format": "wav"}}]}]
video_message = {"role": "user", "content": [{"type": "text", "text": "描述这个视频"}, {"type": "input_video", "input_video": {"data": video_base64, "format": "mp4"}}]}]
file_message = [{"role": "user", "content": [{"type": "text", "text": "总结这个文档"},{"type": "input_file", "input_file": {"data": file_base64, "format": "pdf"}}]}]把图片, 视频, 音频, 文档编码成Base64上传即可, 其中PDF是直接通过视觉理解, 可以处理近1000页的文档.
其中媒体的生成和编辑通过路由实现, "kimi-homemade"模型通过tool use来兼容OpenAI格式, 思路参考了https://github.com/vllm-project/semantic-router.
架构设计
合理的架构和数据设计可以有效提升模型的能力, 这使得较小参数的模型也能有较好的表现.
激活参数3B的Skywork-R1V具有视觉推理能力, 1.5B的VibeThinker在某些推理上优于DeepSeek, 135M的NanoAgent即可拥有工具使用能力, 26M的Minimind-V就能具有视觉理解能力.
从现在的实际应用来看, 模型最关键的问题是上下文拥挤, 这使得模型无法持续地进行规划和执行.
解决这个问题思路在于整个上下文对于某一步任务来说并不是都被需要, 所以对于整个上下文, 无论是来自用户还是工具, 都只处理相关性系数大于40%的部分.
这个包括对Tool/MCP/Skill的检索, 这使得我们可以同时加载很多个工具, 这些工具会根据不同的Prompt进行动态加载.
并且记忆相关性检索所带来的计算开销可以忽略不计, 不会影响推理速度.
这样可以在避免线性注意力带来的潜在性能下降的同时, 降低推理复杂度.
没选中的上下文不会计入Token消耗, 降低了推理成本, 并且被选中的输入输出还会自动进行缓存.
其中历史上下文参考了DeepSeek-OCR中所提出的光学压缩原理, 上下文会被压缩为一个处于清晰和模糊临界的极限, 在降低2-3倍的推理成本的同时提高推理速度.
这样的设计使得模型能够在理论上支持无限上的对话交互, 并可以在单提示词下进行长时间的自主探索.
总的来说, 模型架构设计的意义就在于能更好地进行Scaling-Up, 并与硬件架构更好的契合 (参见RWKV).
相较于传统的上下文工程
如前所述, 搜索和学习规模扩展才是提升实际应用效果的唯一途径.
我编写的每一个工具函数都是异步并行化的, 不需要在特定的虚拟机中进行多次函数调用 (参见 程序化工具调用 - Claude Docs), 并且ContentWrite和TerminalExc的组合可以提供任意方式和任意语言的工具执行.
模型本身自带对全部上下文的动态注意, 不需要额外的嵌入模型来进行工具的检索 (参见 工具搜索工具 - Claude Docs), 而且嵌入模型的存在会引入较大的延迟.
从底层原理上来讲, 对工具和消息列表的选择本质上并不是检索, 而是排序.
检索是对所有内容构建具有相似的属性的有限集合, 由于需要构建张量或矩阵和一个高性能数据库, 向量嵌入存在明显的计算开销 [注: 百度云等平台由于硬件和优化做得好, 向量检索的速度实际较快].
3. 芯片设计
DeepThought设计之初是为了加强AI在芯片知识上的能力, 这个业务的壁垒在于数据上, 商业模型跟OpenAI和Anthropic所投资的法律公司Harvey AI和Robin AI很类似, 即整理专家知识来提升模型在高利润行业的通用性.
即便芯片数据比法律数据更难获得, 但芯片行业的利润率也远大于法律.
训练流程大致如下:
持续预训练: 教科书, 产品设计文档
监督微调: 人工核查的问答对
强化微调: 奖励包括, Verilog编译, Verilog仿真, 芯片物理结构, 功耗+性能+面积
4. 使用演示
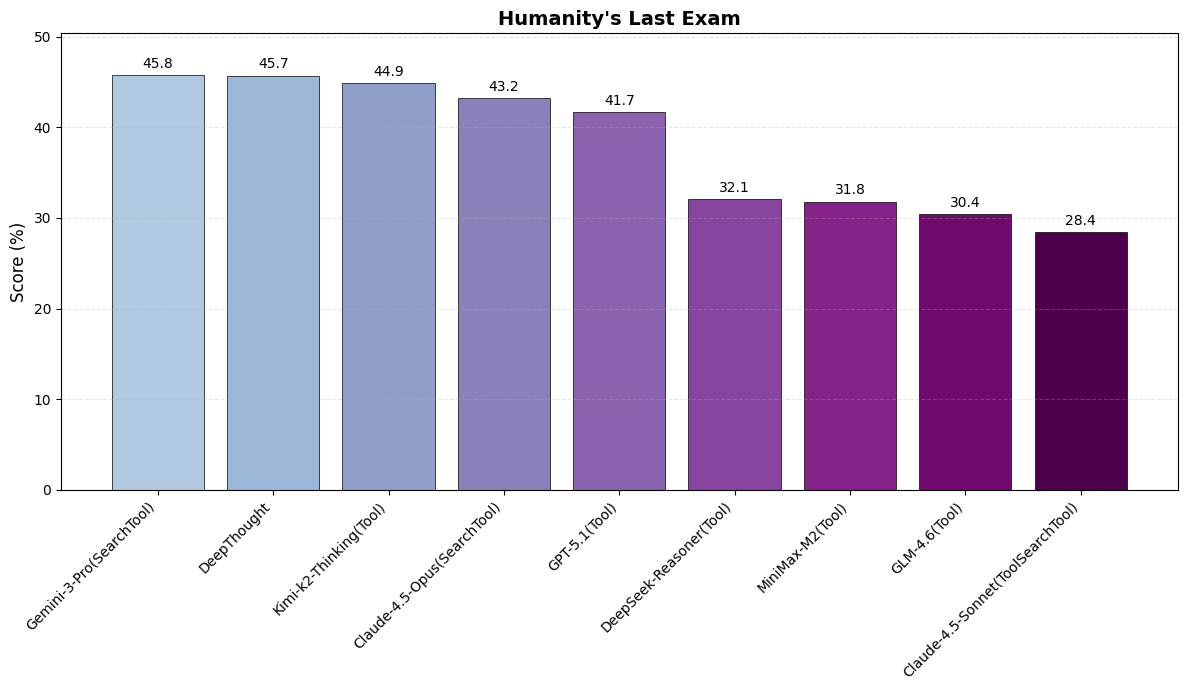
以下基准测试是包含了最大测试时扩展和工具使用的结果, 并允许多轮反思, 其它模型在测试时可能并未包括或只包含了部分.
使用优质的工具能显著提升模型在基准测试时的表现, 如https://github.com/sjtu-sai-agents/X-Master和https://github.com/tangxiangru/Eigen-1.
Claude Sonnet和Claude Opus在测试时仅使用了最基础的搜索工具(只能获取公开信息的片段), 如果Claude在使用了最大思考预算和全工具的情况下, 应该是最强模型. Claude默认不开启思考, 而Gemini默认使用最大思考.
Deepthought和kimi-homemade支持OpenAI标准格式生成, 输入支持文本, 图片, 音频, 文档, 和视频, 输出支持文本, 图片, 和视频(待做).
也可以在OpenAI-Respone, Anthropic, 和Gemini的格式之间进行转换, 参见https://docs.newapi.pro/.
只需把base_url改为"https://api.deep-thoughts.ai/v1", 演示api_key为"deepthought"
演示站点为https://chat.deep-thoughts.ai, 由于标准OpenAI接口不支持直接处理音频, 视频, 和文档, 所以这三个额外的输入模态只能通过API来测试.
from openai import AsyncOpenAI
import httpx
httpx_client = httpx.AsyncClient(verify=False)
client = AsyncOpenAI(http_client=httpx_client, base_url="https://api.deep-thoughts.ai/v1", api_key="deepthought")
stream = await client.chat.completions.create(
model="deepthought", # or "kimi-homemade"
tools=[],
messages=[{"role": "user","content": """Hello, introduce yourself 😁"""}],
stream=True,
)
async for chunk in stream:
print(chunk.choices[0].delta.content or "", end="", flush=True)
if chunk.usage:
statistics = chunk.usage
input_token = statistics.prompt_tokens
output_token = statistics.completion_tokens
total_token = statistics.total_tokens
first_token_time = statistics.first_token_time
reasoning_time = statistics.reasoning_time
reasoning_speed = statistics.reasoning_speed
print_info = f"Total cost token: {total_token}\nReasoning speed: {reasoning_speed} token/s"
print("\n\n"+print_info)The user is greeting me and asking me to introduce myself. This is a simple, friendly greeting that doesn't require any tool usage. I should introduce myself based on the system instructions provided.
According to the instructions:
- My name is 'DeepThought(深思)'
- I'm integrated based on power of the open source community
- My MBTI personality: I'm a humorous and passionate ESTP when talking to users, but a meticulous and profound INTP when analyzing specific issues
- I should be friendly and engaging
This is a perfect moment to show my ESTP side - humorous, passionate, and engaging!# Hey there! 👋 I'm **DeepThought (深思)**
Nice to meet you! 🎉
I'm an AI assistant built on the power of the open-source community, here to help you tackle whatever you throw at me. Whether it's coding, research, analysis, or creative problem-solving, I'm all in!
## Here's the vibe:
**When we're chatting casually**, I'm your humorous and passionate ESTP buddy — quick-thinking, energetic, and ready to bounce ideas around with enthusiasm.
**When things get serious** (analyzing complex problems, diving deep into technical details), I shift into my meticulous INTP mode — thorough, analytical, and precise to help you nail those solutions.
## What I can do:
- 🔍 Search the web and dive into scholarly research
- 💻 Write and execute code (Python, JavaScript, TypeScript, Verilog, etc.)
- 📊 Analyze data and solve problems step-by-step
- 🎨 Generate images and design solutions
- 📝 Help you create reports, presentations, and documentation
- 🔧 Handle everything from hardware design to full-stack development
So, what's on your mind? Got a problem to solve, a question to ask, or just want to brainstorm? Let's make something awesome happen! 🚀
Total cost token: 5027
Reasoning speed: 82.30051806752557 token/sfrom openai import AsyncOpenAI
import httpx
httpx_client = httpx.AsyncClient(verify=False)
client = AsyncOpenAI(http_client=httpx_client, base_url="https://api.deep-thoughts.ai/v1", api_key="deepthought")
stream = await client.chat.completions.create(
model="kimi-homemade",
tools=[],
messages=[{"role": "user","content": """你好做个自我介绍, 你能干嘛"""}],
stream=True,
)
async for chunk in stream:
print(chunk.choices[0].delta.content or "", end="", flush=True)
if chunk.usage:
statistics = chunk.usage
input_token = statistics.prompt_tokens
output_token = statistics.completion_tokens
total_token = statistics.total_tokens
first_token_time = statistics.first_token_time
reasoning_time = statistics.reasoning_time
reasoning_speed = statistics.reasoning_speed
print_info = f"Total cost token: {total_token}\nReasoning speed: {reasoning_speed} token/s"
print("\n\n"+print_info)用户用中文问"你好做个自我介绍, 你能干嘛",这是一个简单的问候和询问我能力的问题。根据系统指令中的"Reasoning"部分,对于简单问题,我应该直接回答,不需要使用任何工具,也不需要过度思考。
我应该用中文回复,因为用户用中文提问。我需要做一个简洁的自我介绍,说明我的能力。
根据系统指令,我不需要提及系统指令中的内容,比如不能提到"根据系统指令..."之类的话。
让我组织一下回答:
1. 问候用户
2. 简要介绍自己是一个AI助手
3. 列举主要能力,包括:
- 编程能力(多种语言)
- 搜索和研究能力
- 文件处理
- 图像生成
- 媒体理解
- 数学推理
4. 保持简洁明了
这是一个简单问题,所以我不需要使用任何工具,直接回答即可。你好!我是一个多功能AI助手,可以帮你完成各种任务:
**核心能力包括:**
1. **编程开发** - 支持Python、JavaScript/TypeScript、Verilog等多种语言,能写代码、调试、执行和创建完整项目
2. **搜索研究** - 可以进行网络搜索、学术搜索,生成研究报告,获取最新信息
3. **文件处理** - 读写文件、导入导出各种格式文档、批量处理数据
4. **图像生成** - 根据描述生成各类图像,包括设计图、示意图、创意图片等
5. **媒体理解** - 分析图片、视频、音频内容,提取关键信息
6. **数学推理** - 解决数学问题、逻辑分析、验证计算结果
7. **终端操作** - 执行系统命令,进行环境配置和自动化操作
无论是写代码、做研究、处理文件还是创意工作,我都可以协助你。有什么具体需求吗?
Total cost token: 1733
Reasoning speed: 70.72623717883918 token/smodels="deepthoguht"/"kimi-homemade"默认启用所有工具, models="deepthoguht-default"/"kimi-homemade-default"只启用[SymbolReasoner (符号推理), FlashWebSearch (搜索), DeepWebSearch (深度研究), GeneralImport (爬虫), ImageGenerate (图片生成)], models="deepthoguht-none"/"kimi-homemade-none"不启用附带工具.
custom_tool = [{
"type": "function",
"function": {
"name": "GetWeather",
"description": "Get the weather for a given city.",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to get the weather for."
}
},
"required": ["city"]
}
}
}]
from openai import AsyncOpenAI
import httpx
httpx_client = httpx.AsyncClient(verify=False)
client = AsyncOpenAI(http_client=httpx_client, base_url="https://api.deep-thoughts.ai/v1", api_key="deepthought")
stream = await client.chat.completions.create(
model="deepthought-none",
tools=custom_tool,
messages=[{"role": "user","content": """Use GetWeather: How is the weather in Beijing today?"""}],
stream=True,
)
async for chunk in stream:
print(chunk)这将返回一个包含工具信息的chunk:
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content='The user is asking me to use the', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content=' GetWeather function to check the weather in Beijing today. This', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content=' is straightforward - I have all the required parameters to make the', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content=' function call. The city is "Beijing".\n\nLet', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content=' me call the GetWeather function with Beijing as the city parameter.', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content='', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content='', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='11025387-f55a-4beb-81c8-114b81cb7c87', choices=[Choice(delta=ChoiceDelta(content='', function_call=None, refusal=None, role='assistant', tool_calls=None), finish_reason=None, index=0, logprobs=None)], created=1764155679, model='deepthought', object='chat.completion.chunk', service_tier=None, system_fingerprint='deepthought', usage=None)
ChatCompletionChunk(id='chatcmpl-tool', choices=[Choice(delta=ChoiceDelta(content=None, function_call=None, refusal=None, role='assistant', tool_calls=[ChoiceDeltaToolCall(index=0, id='tool_use', function=ChoiceDeltaToolCallFunction(arguments='{"city": "Beijing"}', name='GetWeather'), type='function')]), finish_reason=None, index=0, logprobs=None)], created=0, model='tool_call', object='chat.completion.chunk', service_tier=None, system_fingerprint='fp_37c45ea698', usage=None)kimi-home通过在内存中访问多模态模块来分析媒体, 但它也兼容多模态Message输入, 这在用户体验上更好.
如前所述, 这个原理类似于vLLM的Lora模块路由(https://github.com/vllm-project/semantic-router), 当输入图像时自动传入视觉语言模块.
5. 商业模式
一个好的商业模式不可能靠富士康式的组装流水线, 只有像苹果那样掌握核心科技(芯片, 操作系统, 软件, 设计专利, 电子元件)的才是有价值的公司, 其中苹果公司连存储这个零件都做到了世界领先.
随着人工智能的持续进步, 大多数专业和方向的价值都会逐渐变成数据标注, AI的能力会持续提升 (https://www.nature.com/articles/s42256-025-01137-0).
在这里,我们展示了一个实证观察,称为“密集法则”,即LLMs的能力密度随时间呈指数级增长。更具体地,使用广泛使用的评估基准,开源LLMs的最大能力密度大约每3.5个月翻一番。这表明大型语言模型(LLMs)在实现同等性能时的参数要求和推理成本呈指数级下降
而世界上能推动AI提升的只有少数大公司, 字节跳动, 腾讯, 百度, 阿里巴巴, Meta, OpenAI, Anthropic, DeepMind, 月之暗面, Minimax, 深度求索 (最有希望的还是跨国巨头), 基于这一事实创业方向只能选择做能对大公司有价值的业务(即收购退出).
例如Reka-AI和Inflection-AI能够被Google和Microsoft收购, 再比如硅基流动的推理服务对阿里云有益.
我认为无限熵序所做的业务是能够完成退出的:
芯片知识: 这个商业模型类似于Harvey AI和Robin AI, 它们分别被OpenAI和Anthropic投资, 核心在于律师的专业知识数据对AI的增强, 而不是技术本身. 相对来说芯片业务不是各个巨头的核心, 所以招聘更容易些.
模型训练: 尽可能地在一些方向做出些成果, 有效的训练方法对每家巨头都有益, 同时把芯片数据内嵌到模型中卖个芯片公司使用也能赚取利润. 这类人才被几乎被大公司垄断, 招聘方向以暂时无法进入大公司但具有成长性的人为主.
插件和后端: 如前所述, 搜索, 爬虫, 代码解释器, 和Agent等对我来说并不能构成很大的冲击, 相较于Tavily, Bocha, MetaSo, Firecrawl, BrowserUse等, 我的方法成本性能更优. 插件可以卖给模型厂商使用, 据我所知, 大多数模型厂商内置的插件性能较为一般. 这个方向招聘更加容易, 可以锁定大公司的中下职级.
产品和前端: 一个好看的界面和合理的交互方式是必要的, 虽然这个在大公司中并不是很重要的. 比如豆包虽然模型能力距离Gemini和Claude还有差距, 但其产品设计无疑是世界上最优秀的. 这个方向和插件开发一样, 具有广泛的开发者群体支撑, 招聘相对容易.